
December 20, 2021
In this commentary, originally posted on VoxEU, Nishant Yonzan, Branko Milanovic, Salvatore Morelli, and Janet Gornick analyze when and why household survey data and tax data diverge at the top of the income distribution.
By Nishant Yonzan, Branko Milanovic, Salvatore Morelli, Janet Gornick
Household survey data have been widely used for understanding, among other things, the welfare of individuals and families within and across countries. However, as is well known, household surveys do not fully capture the top of the income distribution – whether due to misreporting or various forms of non-response (i.e. refusal to participate or to provide specific information) (e.g. Korinek et al. 2006, Lustig 2020, Ravallion 2021). The existing literature suggests that tax data lead to estimates of top income shares that are generally larger than those found using household survey data (e.g. Burkhauser et al. 2012 for the U.S. comparing CPS data to tax-based estimates from Piketty and Saez 2003, Bartels and Metzing 2019 for Germany, and Burkhauser et al. 2017 for the UK).
Tax data are also not immune to measurement concerns arising from, among other factors, tax exemptions, evasion, avoidance, and misreporting (e.g. Piketty et al. 2011). Furthermore, definitions of income in tax data vary as a function of the types of income that are taxed in a given country and time; the nature of tax units also depends on overarching rules, such as whether couples can file jointly, separately, or both.
It has been argued that combining the two data sources can produce better estimations of the distribution of income. The difficult part, however, is knowing where discrepancies occur and why.1 Two questions thus arise: (1) at what point in the income distribution does the gap in income between survey and tax data become problematic such that using tax data is beneficial? (the where); and (2) what is the source of this gap? (the why).
Exploring this in detail is difficult because of differing definitions of income and recipient units. However, thanks to the flexibility of harmonized microdata available from the Luxembourg Income Study (LIS) Database, it is possible to use household survey data to fully match (‘mimic’) the relevant tax data, and to uncover the sources of discrepancies. In a recent paper (Yonzan et al. 2021), using survey-based data from the LIS Database and income tax data from various sources (for the U.S., Piketty and Saez 2001, Saez 2015), we find that the discrepancy arises only at the very top of the income distribution. The main source of discrepancy is non-labor income, and the reason for changes in this discrepancy over time appears to be the elasticity of taxable incomes to tax policies.
In what follows, we first lay out the necessary adjustments to the data that would allow an apples-to-apples comparison between income from survey data and income from tax data. With those adjustments in place, we then investigate where in the income distribution the disparities begin. And finally, we discuss why these discrepancies might occur and are changing over time. In our paper, we present results for France, Germany, and the United States. Here we discuss these results for the United States.
There are several reasons why estimates of top income shares may diverge between tax and survey data. First, as already mentioned, the income definitions may differ. Second, the units of analysis – tax units versus household survey units – may differ. Third, the two types of data are plagued by different under-reporting problems. Whereas tax data suffer from tax exemptions, evasion, and avoidance, household survey data suffer from misreporting, and different forms of non-response. Fourth, even in the absence of non-response problems, household survey data may return biased estimates of top income shares if their sampling frame does not allow for adequate sampling of rich households. While the first two are mechanical differences and easier to correct, the latter two are behavioral and statistical in nature and require more assumptions.
Thanks to the flexibility of the LIS microdata, we are able to minimize the mechanical discrepancies between the two data sources – namely, the use of different units and different income definitions. Figure 1 compares the number of units in household survey data (Survey-raw) to the number of units in tax data (Tax-raw) for the U.S. in 2013. The center bar is reconstructed from survey households to match the definition of units in the tax data, which are couples and/or single adults with or without dependents. Using surveys, we estimate incomes for 160.9 million U.S. units versus 163 million units that report their income to the U.S. Internal Revenue Service. Similarly, utilizing the flexibility of the LIS data, we construct income from survey data to match the definition of income reported to tax authorities.
Having made these mechanical adjustments, we are better able to compare the resulting incomes from survey and tax data. However, we do note that the behavioral and statistical issues remain, and these issues could very well be contributing to the discrepancies in our findings.
Figure 1 Number of units of analysis in survey and tax data for the U.S. in 2013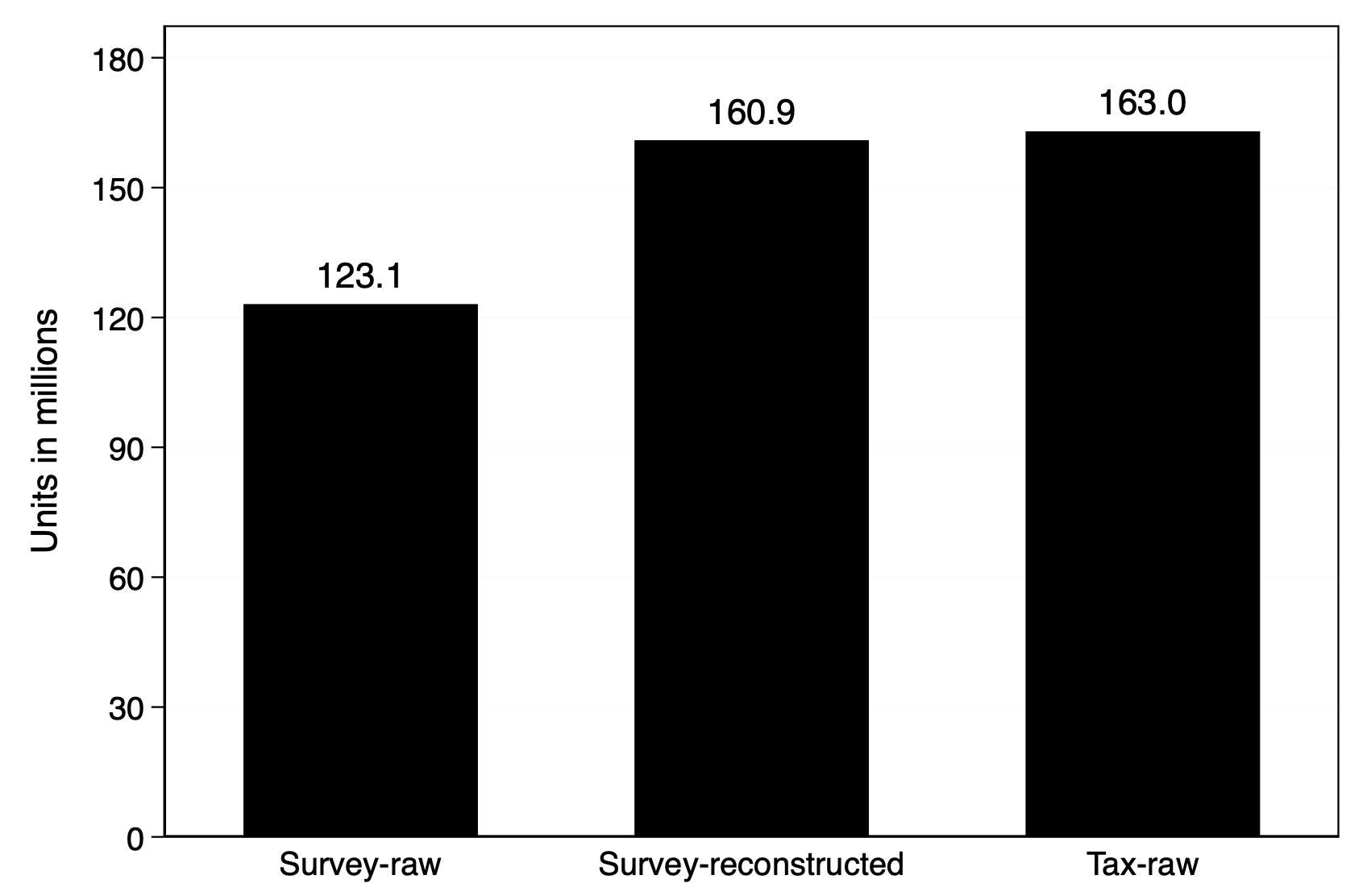
Notes: This figure shows the total number of units in the U.S. in 2013. The total number of households (Survey-raw) is the aggregate (weighted) number of households in the LIS U.S. 2013 dataset; the Survey-reconstructed is the total number of tax units constructed to match the tax data; and the Tax-raw is the total units in tax data. The units are presented in millions.
Where is the gap?
We find that, in the United States, the gap between survey and tax incomes is problematic only for the very top percentile of the income distribution. Figure 2 compares the trends in income shares of the top income groups – namely, the top 1% and the top 4% below the top 1% (top 5–1%) – in the two data sources. While there is a gap in income shares calculated using the two data sources for the top 1%, this gap is minimal, if any, for the top 5–1%. Note also that this gap has been growing over time. Figure 2 additionally highlights the Tax Reform Act of 1986 (TRA 1986), which provided incentives for shifting income between various sources of reported income (Atkinson et al. 2011). Income shifting – that is, reporting a type of income in one tax category in one year and then shifting it to another category in another year in order to minimize tax liability – could be one reason for the increasing gap in the income share of the top 1% group between the survey and tax data. This example shows how changes in tax policies, which induce changes in behavior, can wreak havoc on the observed composition of income.
Figure 2 Trends in income share of top income groups in the U.S.
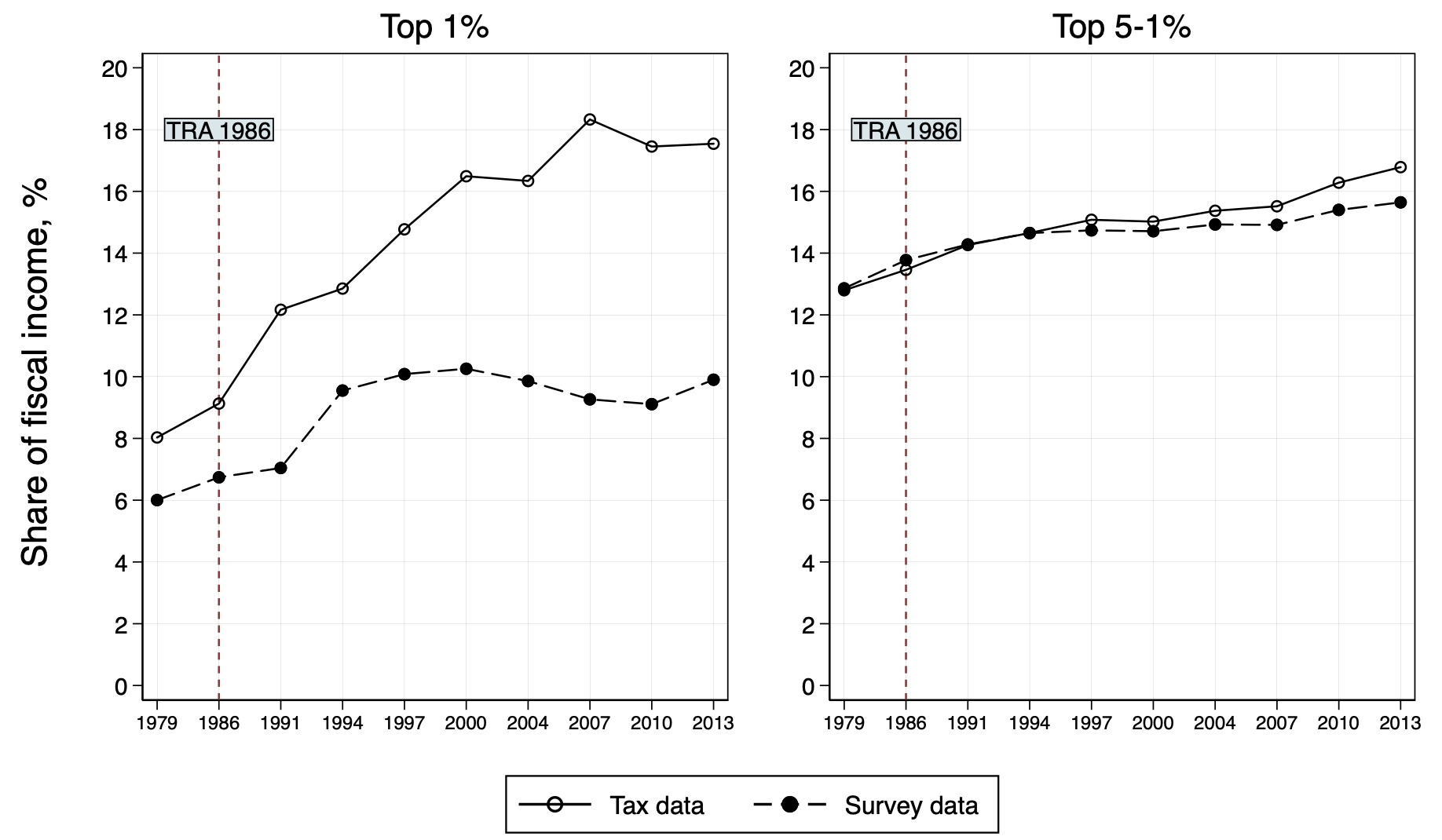
Notes: This figure shows the trend in the shares of the fiscal income held by the top 1% and the next 4 percentile of top earners (top 5-1%) in the U.S. using the survey and tax data. The vertical line at 1986 highlights the year that the Tax Reform Act of 1986 (TRA 1986) was passed in the U.S.
Why does the gap exist?
Why would tax incentives such as TRA 1986 affect mainly the very rich? It is because the rich have more of their income stemming from non-labor sources (which includes business and capital incomes). Figure 3 shows the shares of income from labor and non-labor for the U.S. in 2013. It compares three groups from within the top income decile. While, for the nine percentiles below the top one, the shares of income derived from labor and non-labor are nearly the same in the two sources, within the richest percentile, the non-labor portion of income is significantly greater in the tax data. The source of the rising gap also lies in non-labor income. Whereas in 1986, the year TRA 1986 was passed, only half of the gap between the survey and tax data was due to the non-labor income component (with none of this attributable to business income), by 2013, four fifths of the gap was attributable to non-labor income (with more than three fifths directly due to business income).2
Figure 3 Comparison of income composition for top income groups in the U.S. in 2013
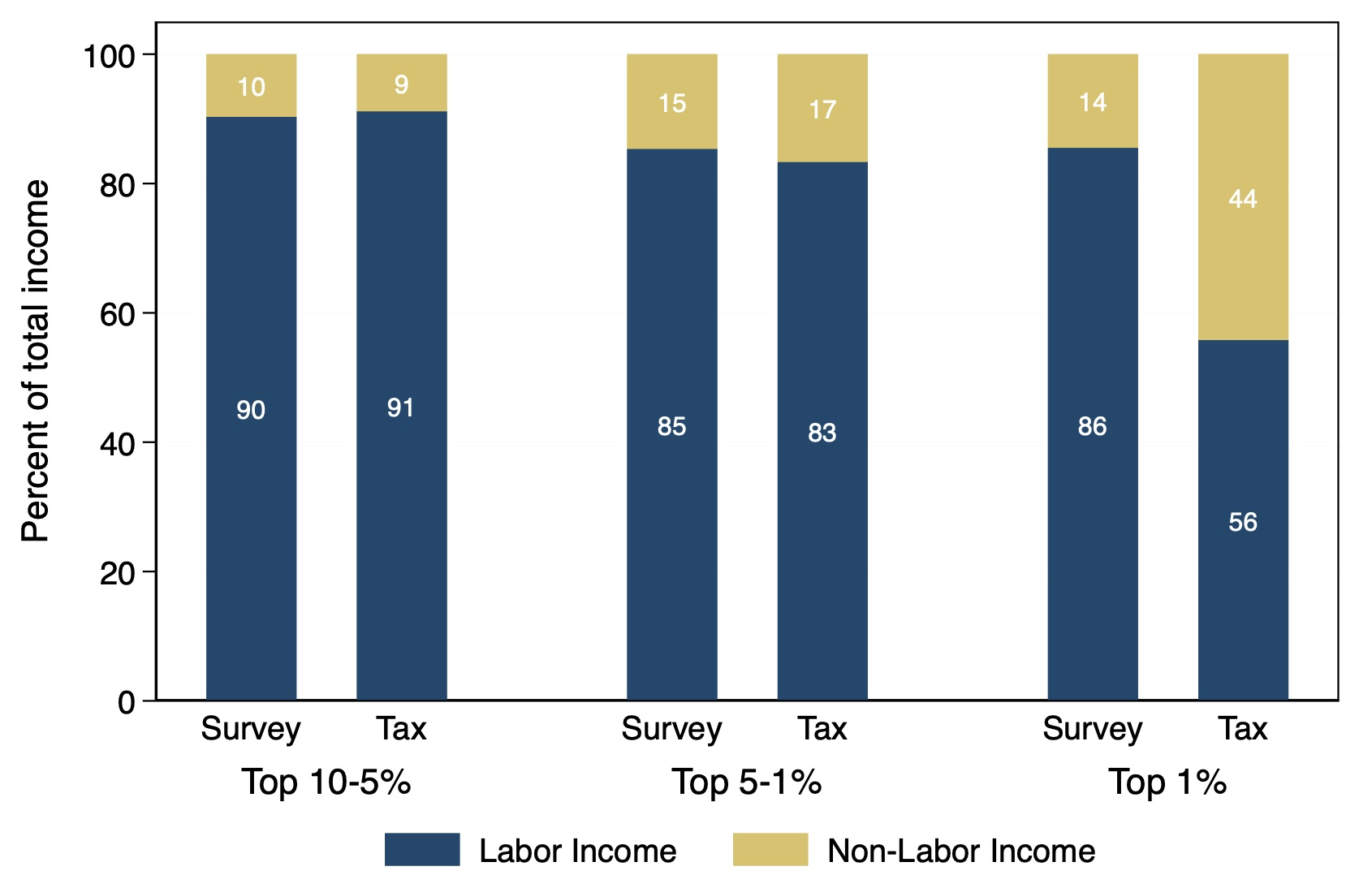
Notes: This figure shows the disaggregation of total income (in percent) by income components (labor and non-labor) held by each income groups in the U.S. for the year 2013. Income groups represent the top percentile (top 1%), the next four percentiles (top 5-1%), and the bottom five percentiles of the top decile (top 10-5%). Non-labor income includes income from business (or self-employment) and income from capital.
Conclusions
What conclusions can we draw based on this evidence? First, for 99% of the population, survey and tax data agree, both in absolute amounts of income (not shown here, but discussed in our paper) and in shares of labor and non-labor income. (The divergence appears only for the top 1% of the population.) Second, the source of that divergence lies in non-labor income only. Third, the cause of the divergence over time appears to be income-shifting due to a change in tax rules. The last point, if confirmed, highlights the problem of using income and income components from tax data in temporal analysis without acknowledging the fact that both are ‘endogenous,’ in the sense that they are affected by public policy changes in how various income sources are taxed. Another possible source of discrepancy is tax evasion and/or avoidance, but we cannot assess that directly due to data limitations.
References
Atkinson, A B, T Piketty and E Saez (2011), “Top Incomes in the Long Run of History,” Journal of Economic Literature 49(1): 3-71.
Bartels, C and M Metzing (2019), “An Integrated Approach for a Top-Corrected Income Distribution,” The Journal of Economic Inequality 17(2): 125–43.
Blanchet, T, I Flores and M Morgan (2018), “The Weight of the Rich: Improving Surveys Using Tax Data,” WID World Working Paper Series, no. 2018/12.
Bourguignon, F (2018), “Simple Adjustments of Observed Distributions for Missing Income and Missing People,” The Journal of Economic Inequality 16(2): 171–88.
Burkhauser, R V, S Feng, S P Jenkins and J Larrimore (2012), “Recent Trends in Top Income Shares in the United States: Reconciling Estimates from March CPS and IRS Tax Return Data,” Review of Economics and Statistics 94(2): 371–88.
Burkhauser, R V, N Hérault S P Jenkins and R Wilkins (2017), “Top Incomes and Inequality in the UK: Reconciling Estimates from Household Survey and Tax Return Data,” Oxford Economic Papers 70(2): 301–26.
Kopczuk, W and E Zwick (2020), “Business incomes at the top,” Journal of Economic Perspectives 34(4): 27-51.
Korinek, A, J A Mistiaen and M Ravallion (2006), “Survey Nonresponse and the Distribution of Income,” Journal of Economic Inequality 4(1): 23.
Lustig, N (2020), “The Missing Rich in Household Surveys: Causes and Correction Approaches,” Paris School of Economics, Mimeo.
Piketty, T and E Saez (2001), “Income inequality in the United States, 1913-1998,” NBER Working Paper Series, No. 8467.
Piketty, T and E Saez (2003), “Income Inequality in the United States, 1913–1998,” The Quarterly Journal of Economics 118(1): 1–41.
Piketty, T, E Saez, S Stantcheva (2011), “Taxing the 1%: Why the top tax rate could be over 80%”, VoxEU.org, 8 December.
Piketty, T, E Saez and G Zucman (2017), “Economic growth in the US: A tale of two countries“, VoxEU.org, 29 March.
Ravallion, M (2021), “Rich non-responders in surveys”, VoxEU.org, 24 June.
Saez, E (2015), “Striking it Richer: The Evolution of Top Incomes in the United States (Updated with 2013 preliminary estimates),” WID World Technical Note Series, No. 2015/1.
Yonzan, N, B Milanovic, S Morelli and J Gornick (forthcoming), “Drawing a line: comparing the estimation of top incomes between tax data and household survey data,” Journal of Economic Inequality.
Endnotes
1 For examples of recent attempts to combine the two data sources, see Blanchet et al. (2018), Bourguignon (2018), Lustig (2020), and Piketty et al. (2017).
2 TRA 1986 created substantial incentives for closely held businesses to shift income from corporate to entities taxed at the individual level (e.g. business profits of an S-corporation are passed through the owners each year so that business income falls under the individual income tax). Kopczuk and Zwick (2020) report that C-corporations decreased from 2.2 million in 1980 to 1.6 million in 2012; at the same time number of partnerships increased from 1.4 million to 3.4 million and S-corporations increased from 0.5 to 4.2 million.
